Methods to Assess Cybersecurity Risks
Posted on July 6, 2020 • 10 min read • 1,936 words
This post shall give you an overview of methods to assess the cybersecurity risks of your products or services. We will go through the development of risk analysis and try to understand why every part is there and what you need it for. Before we start, please be aware, this will not give you a one fits all approach or will cover the complete research from this field. Rather the goal is to make you understand what it takes to assess your IT security risks as well as prepare you to conduct basic risk assessments in the fastest and easiest way possible. So let’s directly jump in.
In the following Sections, I introduce and give examples for different approaches on how to get an overview of possible IT security threats to your systems.
Directly assessing risks
Throughout this post we will use and come back to one very specific use case. This will serve us as an example to better understand the single steps.
A developer uses his own laptop running the Ubuntu operating system to develop a web application for a company. For this, he uses Visual Studio Code as a development environment and a mariadb database (SQL database) as part of his backend. The web application itself uses HTML, CSS, and JS on the frontend and PHP on the backend. For testing and the later deployment he uses an apache web server. Finally, the developer already knows about IT security and employs only secured connections using TLS1.2 and server-side certificates." “Web development use case
For a direct risk assessment, we could now try and start to come up with possible problems. Just by looking at the example description several problems come to mind:
- A public exposure of the database may allow for unallowed data access.
- A misconfigured web server may leak (confidential) data.
- If the web application gets input from an end user to build up database queries, there is a risk of SQL injections.
- etc. After establishing that list, we can now rate the associated risk with each threat, e.g. on a scale from low to high.
This approach has a quite obvious problem. Because you can only come up with an extensive list of possible risks if you bring a lot of experience. Therefore, the risk analyst must have already a feeling on what might go wrong given this setup. This method, hence, can only be useful as a first guess in a very brief discussion of the overall system. For other settings, a more methodological approach is needed.
Asset-based assessment
As first step, many risk assessment methods consider the establishment of a list of assets which are worth protecting. In our example from above such a list could be:
- the developed code of the web application (may be intellectual property)
- the private keys of the web server (during development and production use)
- data stored in the database
- data stored on the web server (machine)
STRIDE
Given this list, we could now think about possible threats to these assets. The probably most common tool to do so is STRIDE developed by Microsoft. STRIDE stands for
- Spoofing
- Tampering
- Repudiation
- Information Disclosure
- Denial of Service
- Elevation of Privilege With this information, we can start out our first basic method. Let’s put the assets in a formatted table.
| ID | Name | Description |
|---|---|---|
| A1 | Code | Developed code of the web application |
| A2 | DKey | Private key of the web server (development) |
| A3 | PKey | Private key of the web server (production) |
| A4 | DB | Data stored in the database |
| A5 | WS | Data stored on the web server (machine) |
| Assets in our example. |
Threats
For each of these assets, we can now evaluate whether the STRIDE threats apply. Let’s do this.
| Asset | Threat | Description | Realistic? |
|---|---|---|---|
| A1 | S | Spoofing of code | How would you spoof this? — not really… |
| A1 | T | Tampering with code | Could be possible with a manipulated compiler, operating system or development IDE. |
| A1 | R | Repudiation of the code | As the code in our example is not signed or anything comparable by the developer — yes. |
| A1 | I | Information disclosure of the code | A manipulated IDE might upload (parts of) the code to untrusted repositories. |
| A1 | D | Denial of service of the code | This would assume that there is no backup of the development code. With current versioning systems most of the times being used, this is rather unlikely. |
| A1 | E | Elevation of privilege of the code | Well, that does not make sense. |
| A2 | S | Spoofing of the DKey | You cannot spoof the private key. It’s unique and a different key would not match the server certificate. |
| A2 | T | Tampering with DKey | A manipulated private key would not work. |
| A2 | R | Repudiation of DKey | Makes no sense. |
| A2 | I | Information Disclosure of DKey | Yes, then all development tests could potentially run against a wrong test server. |
| A2 | D | Denial of Service of DKey | This might only delay testing of the web application. Not dramatic. |
| A2 | E | Elevation of Privilege of DKey | Makes no sense. |
| Threats to the system. |
With this list of threats we can now once again rate the risk associated with each threat qualitatively on a scale. Like in the previous example, we still need to assess this with our experts’ knowledge.
Cumbersome threat lists
Well, ok. I cheated a bit. After only two assets I got exhausted with writing up the threats. When reading through them, you might have noticed a lot of them actually do not really make sense. This is because some of the threats, like Elevation of Privilege of a private key, simply do not make sense. So, if we want to get through this faster we need a better filtering on where to apply which of these threats. I must notice, a lot of people also use violated security goals instead of STRIDE. Then, we would have
- violation of confidentiality (information disclosure)
- violation of integrity (tampering)
- and violation of availability (denial of service)
Meaningful threats
While the list of possible threats is then reduced to half the size, for larger systems this still does not solve the problem of a long list to go through. In order to filter this list even more let’s think about when the different proposed threats are actually relevant. Spoofing happens during data transmission. Either the sender or the receiver could be spoofed. Tampering applies to data in transit, data stored at locations, as well as to functions or processes. Here, a function or a process shall be the logical unit which utilizes and possibly transforms data at any location. Repudiation can happen if data has changed or was transmitted. In these two cases, also information leakage may occur. Denial of Service applies to data transmission and functions or processes. Finally, elevation of privileges does not apply to the system under evaluation but rather to the attacker. It describes an entity carrying out an activity which it was not authorized to. This either requires tampering or spoofing with the system or an authorized user-action combination which becomes unauthorized under certain not modeled constraints.
Goal-based assessments
Before we continue with the next method I want to mention another approach to identify threats to your system which is quite similar to the previous asset-based assessment. Attack trees are an already long-known method to analyze the steps an attacker must perform to reach a goal. In our example we can define different goals of an attacker, e.g. implementing a backdoor in the web application. So let’s think about how he can achieve this.
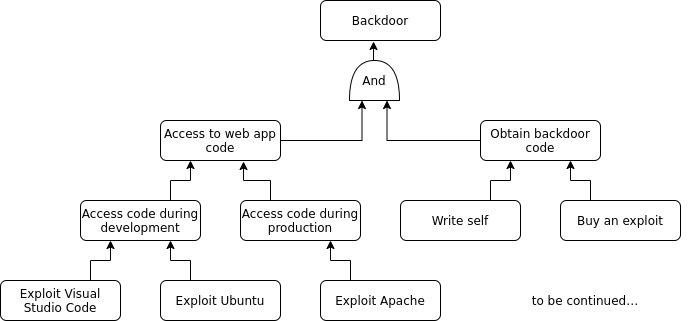
Ok… I admit. Once again I cheated and do not provide the full attack tree but only an excerpt so that you get the idea. Except for the topmost branches from the and node all edges indicate alternatives. To implement the backdoor the attacker needs to get access to the code and have some backdoor code available. All other possible steps have several alternatives to reach these to sub-goals. Compared to the asset-based assessment method, this approach yields a much more fine-grained analysis of the system and potentially shows you already the easiest way for an attacker to break your system.
However, it answers a slightly different question. An attack tree explains how an attacker might reach his goal but not what his goal might be. For the identification of possible goals an asset-based assessment is way more suitable. But attack trees are then a perfect companion for your asset-based assessment if you want to better understand how your assets might be attacked, which controls you may introduce and how hard an attack actually is.
Model-based assessments
So, in the previous sections we explored that for a better mapping of threats we can rely on basic assumptions about the STRIDE threats and refine our system model to data exchanges, stored data, senders, receivers, and functions and processes.
With these refinements, our model now looks a bit more detailed.
| ID | Entity | Description |
|---|---|---|
| E1 | VS Code | Development Environment |
| E2 | Webserver | Apache |
| E3 | DB | MariaDB |
| E4 | User | End-user of web application |
| E5 | Developer | Developer of the web application |
| Entities involved in the system. |
| ID | Data | Description | Stored at |
|---|---|---|---|
| D1 | DKey | Private key of the web server (development) | E1 |
| D2 | PKey | Private key of the web server (production) | E2 |
| D3 | DB | Data stored in the database | E3 |
| D4 | WS | Data stored on the webserver | E2 |
| D5 | Code | Developed code of the web application | E1, E2 |
| D6 | Website | Website evolving from code and DB content | |
| D7 | Input | User input to website | E2 |
| Data stored at different locations in the system. |
| ID | Data Flow | Sender | Receiver | Data |
|---|---|---|---|---|
| F1 | Developer → VS Code: Code | E5 | E1 | D5 |
| F2 | VS Code → Webserver: Code | E1 | E2 | D5 |
| F3 | Webserver → User: Website | E2 | E4 | D6 |
| F4 | User → Webserver: Input | E4 | E2 | D7 |
| F5 | Webserver → DB: Input | E2 | E3 | D7 |
| Data flows between entities of the system. |
| ID | Description | Location | Input | Result |
|---|---|---|---|---|
| G1 | Private key generation (development) | E1 | D1 | |
| G2 | Private key generation (production) | E2 | D2 | |
| G3 | Website generation | E2 | D3, D5 | D6 |
| G4 | User input ingestion | E3 | D7 | D3 |
| G5 | Development | E5 | D5 | |
| Functions and processes generating or manipulating data in the system. |
Advantages
While writing up these tables does not take any effort away compared to the asset-based method, it will serve us quite a bit when rating the risks. First of all, we get a way more detailed picture of the system under evaluation and effectively enable others to understand our reasoning about whether and where one of the STRIDE threats applies. Second, we eliminate many of the previous meaningless threats which did not make sense. And most important, our threats automatically become more granular what makes them easier to asses. If you think about it: it does make a difference — concerning a threat’s likelihood — whether you try to manipulate (tampering) the developed web application code (D5) while it is at rest on VS code (E1) compared to when it is transferred to the web server (F2).
Disadvantages
On the other hand, this model-based assessment requires some efforts in advance to construct the needed system model. However, from my experience I strongly suggest you go this route. Often it is this very step which already shows developers and stakeholders their weaknesses. Especially in big companies it is more often the system complexity which introduces IT security threats instead of missing knowledge.
Until now, we covered a lot of state-of-the-art methods. In the next part of this new series we will touch upon more technical details of the approaches and develop a template for assessments.